-
Type:
Bug
-
Resolution: Unresolved
-
Priority:
 P4
P4
-
Affects Version/s: 8, 9
-
Component/s: javafx
-
x86_64
-
linux
FULL PRODUCT VERSION :
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)
ADDITIONAL OS VERSION INFORMATION :
Linux halberd 3.16.0-4-amd64 #1 SMP Debian 3.16.36-1+deb8u2 (2016-10-19) x86_64 GNU/Linux
EXTRA RELEVANT SYSTEM CONFIGURATION :
Gnome version 3.14.1
A DESCRIPTION OF THE PROBLEM :
All TextInputControl instances have incorrect behavior when copying supplementary characters to the clipboard for use by other applications, and when pasting supplementary characters from the clipboard, which were placed there by other applications.
Supplementary characters are cut, copied and pasted normally, like all other characters, within a single JavaFX application. However:
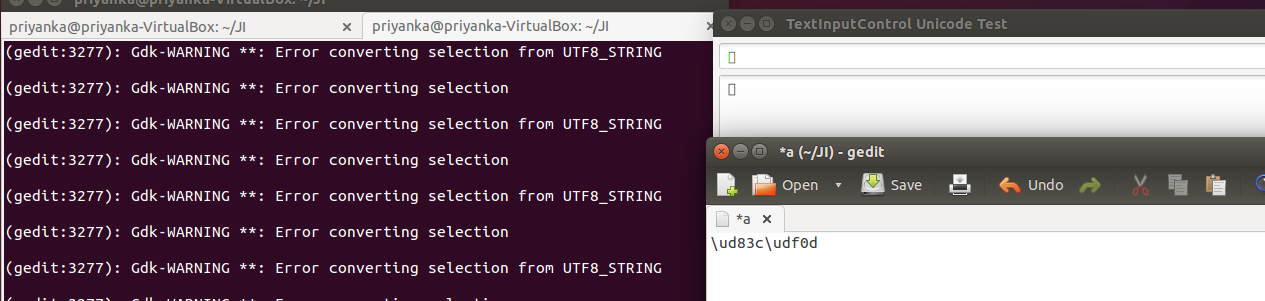
If a supplementary character is placed on the clipboard by a JavaFX application, and pasted into any other application, the other application sees it as two Java language escape sequences representing the corresponding surrogate pair. For example, if a TextField contains the U+1F30F EARTH GLOBE ASIA-AUSTRALIA character, and it is selected and copied, pasting into any text editor (or even another JavaFX application) will cause the twelve characters "\ud83c\udf0f" to be pasted.
If another application places a supplementary character on the clipboard, and one pastes it into a TextField or TextArea, the result appears to be an ISO-8859-1 character corresponding to the first byte of the UTF-8 sequence representing the actual supplementary character. For most currently defined supplementary characters, this is the 0xf0 byte, so only "ð" (U+00F0 LATIN SMALL LETTER ETH) is pasted.
STEPS TO FOLLOW TO REPRODUCE THE PROBLEM :
Initialize any TextField or TextArea with supplementary characters, select them, copy or cut them, and try to paste them into any other application.
Enter supplementary characters directly into another application (I use gedit for this; Ctrl-Shift-U allows entry of any character by its hexadecimal value, including supplementary characters). Select a supplementary character there and copy or cut it. Run any JavaFX application with a TextField or TextArea (including Ensemble.jar) and attempt to paste into it.
EXPECTED VERSUS ACTUAL BEHAVIOR :
EXPECTED -
I expect supplementary characters to be copied and pasted between a JavaFX application and other applications exactly as BMP characters are copied and pasted.
ACTUAL -
Supplementary characters are copied from JavaFX as a Java language escape sequence instead of the actual character; they are pasted into JavaFX as a single byte of the UTF-8 sequence corresponding to the actual character.
REPRODUCIBILITY :
This bug can be reproduced always.
---------- BEGIN SOURCE ----------
import javafx.application.Application;
import javafx.geometry.Insets;
import javafx.stage.Stage;
import javafx.scene.Scene;
import javafx.scene.control.TextArea;
import javafx.scene.control.TextField;
import javafx.scene.layout.BorderPane;
public class TextInputControlUnicodeTest
extends Application {
@Override
public void start(Stage stage) {
TextField textField = new TextField(String.format("%c", 0x1f30d));
TextArea textArea = new TextArea(String.format("%c", 0x1f6b2));
BorderPane pane = new BorderPane(textArea, textField, null, null, null);
pane.setPadding(new Insets(6));
BorderPane.setMargin(textArea, new Insets(6, 0, 0, 0));
Scene scene = new Scene(pane);
stage.setScene(scene);
stage.setTitle("TextInputControl Unicode Test");
stage.show();
}
}
---------- END SOURCE ----------
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)
ADDITIONAL OS VERSION INFORMATION :
Linux halberd 3.16.0-4-amd64 #1 SMP Debian 3.16.36-1+deb8u2 (2016-10-19) x86_64 GNU/Linux
EXTRA RELEVANT SYSTEM CONFIGURATION :
Gnome version 3.14.1
A DESCRIPTION OF THE PROBLEM :
All TextInputControl instances have incorrect behavior when copying supplementary characters to the clipboard for use by other applications, and when pasting supplementary characters from the clipboard, which were placed there by other applications.
Supplementary characters are cut, copied and pasted normally, like all other characters, within a single JavaFX application. However:
If a supplementary character is placed on the clipboard by a JavaFX application, and pasted into any other application, the other application sees it as two Java language escape sequences representing the corresponding surrogate pair. For example, if a TextField contains the U+1F30F EARTH GLOBE ASIA-AUSTRALIA character, and it is selected and copied, pasting into any text editor (or even another JavaFX application) will cause the twelve characters "\ud83c\udf0f" to be pasted.
If another application places a supplementary character on the clipboard, and one pastes it into a TextField or TextArea, the result appears to be an ISO-8859-1 character corresponding to the first byte of the UTF-8 sequence representing the actual supplementary character. For most currently defined supplementary characters, this is the 0xf0 byte, so only "ð" (U+00F0 LATIN SMALL LETTER ETH) is pasted.
STEPS TO FOLLOW TO REPRODUCE THE PROBLEM :
Initialize any TextField or TextArea with supplementary characters, select them, copy or cut them, and try to paste them into any other application.
Enter supplementary characters directly into another application (I use gedit for this; Ctrl-Shift-U allows entry of any character by its hexadecimal value, including supplementary characters). Select a supplementary character there and copy or cut it. Run any JavaFX application with a TextField or TextArea (including Ensemble.jar) and attempt to paste into it.
EXPECTED VERSUS ACTUAL BEHAVIOR :
EXPECTED -
I expect supplementary characters to be copied and pasted between a JavaFX application and other applications exactly as BMP characters are copied and pasted.
ACTUAL -
Supplementary characters are copied from JavaFX as a Java language escape sequence instead of the actual character; they are pasted into JavaFX as a single byte of the UTF-8 sequence corresponding to the actual character.
REPRODUCIBILITY :
This bug can be reproduced always.
---------- BEGIN SOURCE ----------
import javafx.application.Application;
import javafx.geometry.Insets;
import javafx.stage.Stage;
import javafx.scene.Scene;
import javafx.scene.control.TextArea;
import javafx.scene.control.TextField;
import javafx.scene.layout.BorderPane;
public class TextInputControlUnicodeTest
extends Application {
@Override
public void start(Stage stage) {
TextField textField = new TextField(String.format("%c", 0x1f30d));
TextArea textArea = new TextArea(String.format("%c", 0x1f6b2));
BorderPane pane = new BorderPane(textArea, textField, null, null, null);
pane.setPadding(new Insets(6));
BorderPane.setMargin(textArea, new Insets(6, 0, 0, 0));
Scene scene = new Scene(pane);
stage.setScene(scene);
stage.setTitle("TextInputControl Unicode Test");
stage.show();
}
}
---------- END SOURCE ----------
- relates to
-
-
- Open
-