-
Type:
Sub-task
-
Resolution: Won't Fix
-
Priority:
 P4
P4
-
Affects Version/s: 18
-
Component/s: hotspot
Currently, Thread::_rcu_counter is not padded by cacheline, it should be beneficial to do so.
This is to investigate this potential improvement.
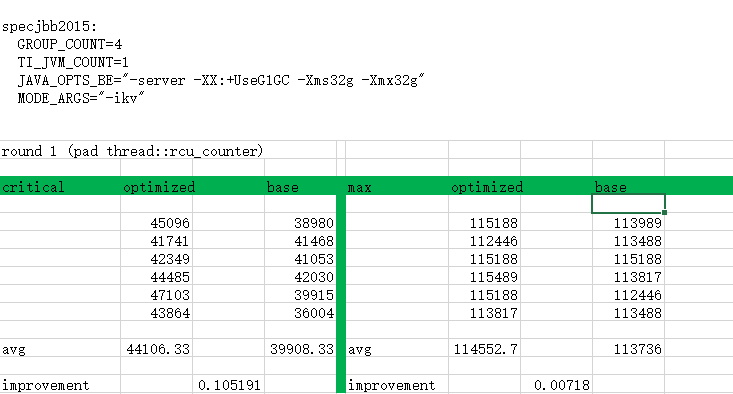
========= specjbb test result (1st round) ==========
rcu base
45096 38980
41741 41468
42349 41053
44485 42030
47103 39915
43864 36004
==== average ====
44106.33333 39908.33333
==== improvement ====
10.5%
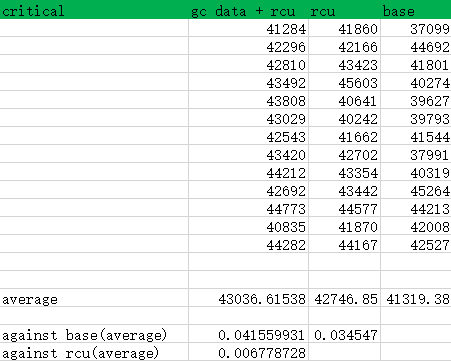
========= specjbb test result (2nd round) ==========
Second round of run includes 3 types:
1. pad gc data & pad rcu
2. pad rcu only
3. base
Although the improvement is not that much as the previous round (10%), but still got about 3~4% improvement.
gc data & rcu rcu base
41284 41860 37099
42296 42166 44692
42810 43423 41801
43492 45603 40274
43808 40641 39627
43029 40242 39793
42543 41662 41544
43420 42702 37991
44212 43354 40319
42692 43442 45264
44773 44577 44213
40835 41870 42008
44282 44167 42527
==== average ====
43036.61538 42746.84615 41319.38462
==== improvement ====
gc data + rcu / base: 4.156%
rcu / base: 3.45%
========= configuration and environment ==========
specjbb arguments:
GROUP_COUNT=4
TI_JVM_COUNT=1
SPEC_OPTS_C="-Dspecjbb.group.count=$GROUP_COUNT -Dspecjbb.txi.pergroup.count=$TI_JVM_COUNT"
SPEC_OPTS_TI=""
SPEC_OPTS_BE=""
JAVA_OPTS_C="-server -Xms2g -Xmx2g -XX:+UseParallelGC"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -XX:+UseG1GC -Xms32g -Xmx32g"
MODE_ARGS_C="-ikv"
MODE_ARGS_TI="-ikv"
MODE_ARGS_BE="-ikv"
NUM_OF_RUNS=1
HW:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 224
On-line CPU(s) list: 0-223
Thread(s) per core: 2
Core(s) per socket: 28
Socket(s): 4
NUMA node(s): 4
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8176M CPU @ 2.10GHz
Stepping: 4
CPU MHz: 1001.925
CPU max MHz: 2101.0000
CPU min MHz: 1000.0000
BogoMIPS: 4200.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 39424K
NUMA node0 CPU(s): 0-27,112-139
NUMA node1 CPU(s): 28-55,140-167
NUMA node2 CPU(s): 56-83,168-195
NUMA node3 CPU(s): 84-111,196-223
total used free shared buff/cache available
Mem: 3.0T 3.8G 2.9T 18M 25G 2.9T
Swap: 99G 0B 99G
OS:
Linux 4.15.0-159-generic
This is to investigate this potential improvement.
========= specjbb test result (1st round) ==========
rcu base
45096 38980
41741 41468
42349 41053
44485 42030
47103 39915
43864 36004
==== average ====
44106.33333 39908.33333
==== improvement ====
10.5%
========= specjbb test result (2nd round) ==========
Second round of run includes 3 types:
1. pad gc data & pad rcu
2. pad rcu only
3. base
Although the improvement is not that much as the previous round (10%), but still got about 3~4% improvement.
gc data & rcu rcu base
41284 41860 37099
42296 42166 44692
42810 43423 41801
43492 45603 40274
43808 40641 39627
43029 40242 39793
42543 41662 41544
43420 42702 37991
44212 43354 40319
42692 43442 45264
44773 44577 44213
40835 41870 42008
44282 44167 42527
==== average ====
43036.61538 42746.84615 41319.38462
==== improvement ====
gc data + rcu / base: 4.156%
rcu / base: 3.45%
========= configuration and environment ==========
specjbb arguments:
GROUP_COUNT=4
TI_JVM_COUNT=1
SPEC_OPTS_C="-Dspecjbb.group.count=$GROUP_COUNT -Dspecjbb.txi.pergroup.count=$TI_JVM_COUNT"
SPEC_OPTS_TI=""
SPEC_OPTS_BE=""
JAVA_OPTS_C="-server -Xms2g -Xmx2g -XX:+UseParallelGC"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -XX:+UseG1GC -Xms32g -Xmx32g"
MODE_ARGS_C="-ikv"
MODE_ARGS_TI="-ikv"
MODE_ARGS_BE="-ikv"
NUM_OF_RUNS=1
HW:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 224
On-line CPU(s) list: 0-223
Thread(s) per core: 2
Core(s) per socket: 28
Socket(s): 4
NUMA node(s): 4
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8176M CPU @ 2.10GHz
Stepping: 4
CPU MHz: 1001.925
CPU max MHz: 2101.0000
CPU min MHz: 1000.0000
BogoMIPS: 4200.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 39424K
NUMA node0 CPU(s): 0-27,112-139
NUMA node1 CPU(s): 28-55,140-167
NUMA node2 CPU(s): 56-83,168-195
NUMA node3 CPU(s): 84-111,196-223
total used free shared buff/cache available
Mem: 3.0T 3.8G 2.9T 18M 25G 2.9T
Swap: 99G 0B 99G
OS:
Linux 4.15.0-159-generic
{kind=link}
{kind=link}
- relates to
-
JDK-8276616 Investigate and optimize GlobalCounter/SingleWriterSynchronizer related things
-
- Closed
-
-
-
- Closed
-
- links to
-
 Review
openjdk/jdk/6246
Review
openjdk/jdk/6246