-
Type:
Bug
-
Resolution: Fixed
-
Priority:
 P4
P4
-
Affects Version/s: 26
-
Component/s: core-libs
-
None
A huge performance difference was found between submitting empty tasks to platform FJP and executing such tasks in virtual threads on many-core machines.
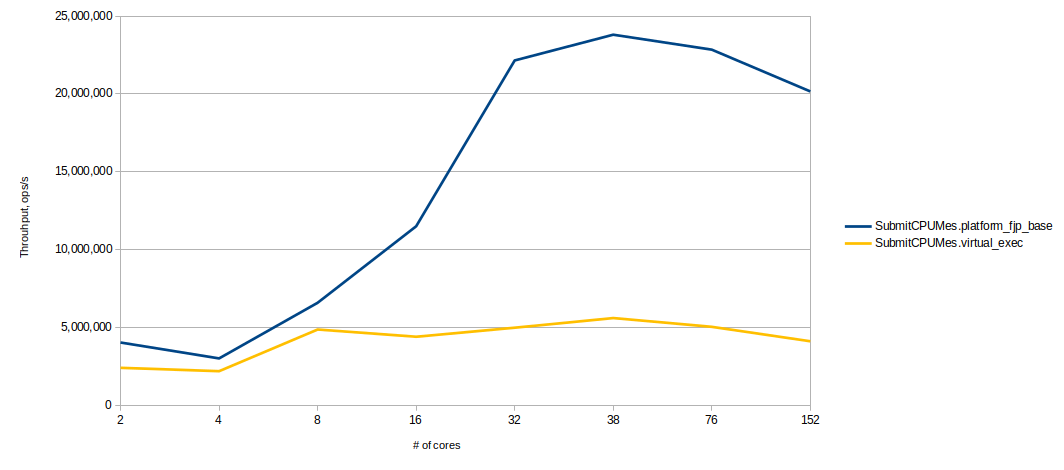
Here is the performance chart on Intel Xeon 8368, 38 cores, HT, 2 NUMA nodes, 2x38x2 hw threads.
JVM is limited to a different number of cores.
The performance difference was observed starting from 16 cores.
E.g. on 32 cores platform threads FJP is 4.4x times faster than executing the same actions in virtual threads.
(Note: performance drop down after 38 cores is explained by crossing NUMA boundary).
All further explanation was made for 32 cores case.
In the virtual thread case, the source of the slowdown is the ForkJoinPool::signalWork invocation.
The single assembly CAS operation takes 17% of all CPU cycles.
The call stack is:
17.12% ;*invokevirtual compareAndExchangeLong {reexecute=0 rethrow=0 return_oop=0}
; - java.util.concurrent.ForkJoinPool::compareAndExchangeCtl@9 (line 1672)
; - java.util.concurrent.ForkJoinPool::signalWork@149 (line 1893)
; - java.util.concurrent.ForkJoinPool$WorkQueue::push@172 (line 1302)
; - java.util.concurrent.ForkJoinPool::poolSubmit@70 (line 2625)
; - java.util.concurrent.ForkJoinPool::execute@27 (line 3179)
; - java.lang.VirtualThread::submitRunContinuation@50 (line 345)
; - java.lang.VirtualThread::externalSubmitRunContinuationOrThrow@58 (line 430)
; - java.lang.VirtualThread::start@52 (line 700)
; - java.lang.VirtualThread::start@4 (line 705)
In the platform FJP case, the same asm instruction takes 1.8%.
1.78% ;*invokevirtual compareAndExchangeLong {reexecute=0 rethrow=0 return_oop=0}
; - java.util.concurrent.ForkJoinPool::compareAndExchangeCtl@9 (line 1672)
; - java.util.concurrent.ForkJoinPool::signalWork@149 (line 1893)
; - java.util.concurrent.ForkJoinPool$WorkQueue::push@172 (line 1302)
; - java.util.concurrent.ForkJoinPool::poolSubmit@70 (line 2625)
; - java.util.concurrent.ForkJoinPool::submit@51 (line 3241)
; - java.util.concurrent.ForkJoinPool::submit@2 (line 200)
Due to this induced CAS contention on the "ctl" field, all other places where "clt" is accessed take an additional 41% of CPU cycles in the virtual thread case. In the platform FJP case, the cost of additional access to "ctl" is ~2.4% of CPU cycles.
It was found that the behavior difference can be explained by wrapping actions into AdaptedRunnable or AdaptedInterruptibleRunnable ForkJoinTasks.
For submitting from external threads, AdaptedInterruptibleRunnable is used.
InterruptibleRunnable has significantly less signalWork impact than AdaptedRunnable.
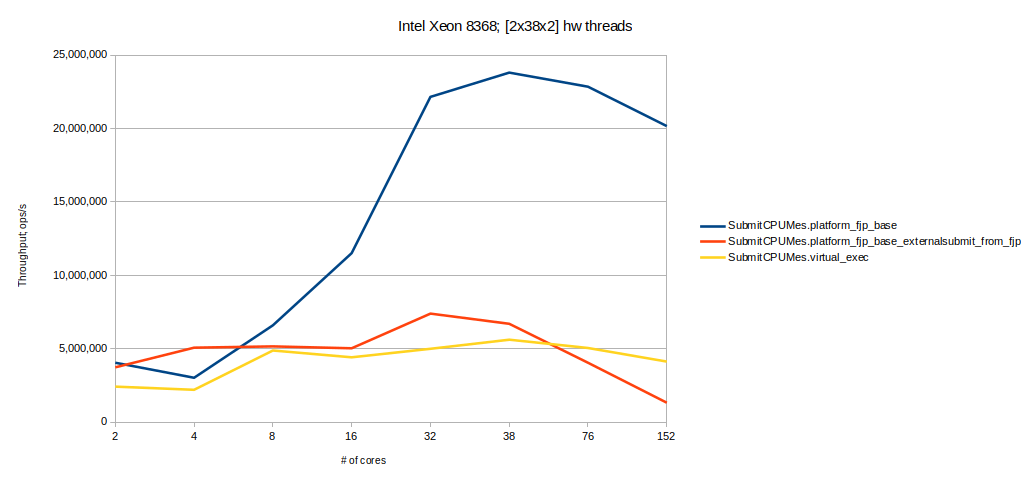
The simplest way to recheck this is to run the platform FJP benchmark, and perform the submit operation from the other FJP pool. Running it in such a way, from the FJP thread, the AdaptedRunnable wrapper is used, but since the other FJP is used, the submit stays interpreted as an external submit.
Here is the chart, and the platform FJP benchmark with AdaptedRunnable behaves the same way as virtual threads.
Here is the performance chart on Intel Xeon 8368, 38 cores, HT, 2 NUMA nodes, 2x38x2 hw threads.
JVM is limited to a different number of cores.
The performance difference was observed starting from 16 cores.
E.g. on 32 cores platform threads FJP is 4.4x times faster than executing the same actions in virtual threads.
(Note: performance drop down after 38 cores is explained by crossing NUMA boundary).
All further explanation was made for 32 cores case.
In the virtual thread case, the source of the slowdown is the ForkJoinPool::signalWork invocation.
The single assembly CAS operation takes 17% of all CPU cycles.
The call stack is:
17.12% ;*invokevirtual compareAndExchangeLong {reexecute=0 rethrow=0 return_oop=0}
; - java.util.concurrent.ForkJoinPool::compareAndExchangeCtl@9 (line 1672)
; - java.util.concurrent.ForkJoinPool::signalWork@149 (line 1893)
; - java.util.concurrent.ForkJoinPool$WorkQueue::push@172 (line 1302)
; - java.util.concurrent.ForkJoinPool::poolSubmit@70 (line 2625)
; - java.util.concurrent.ForkJoinPool::execute@27 (line 3179)
; - java.lang.VirtualThread::submitRunContinuation@50 (line 345)
; - java.lang.VirtualThread::externalSubmitRunContinuationOrThrow@58 (line 430)
; - java.lang.VirtualThread::start@52 (line 700)
; - java.lang.VirtualThread::start@4 (line 705)
In the platform FJP case, the same asm instruction takes 1.8%.
1.78% ;*invokevirtual compareAndExchangeLong {reexecute=0 rethrow=0 return_oop=0}
; - java.util.concurrent.ForkJoinPool::compareAndExchangeCtl@9 (line 1672)
; - java.util.concurrent.ForkJoinPool::signalWork@149 (line 1893)
; - java.util.concurrent.ForkJoinPool$WorkQueue::push@172 (line 1302)
; - java.util.concurrent.ForkJoinPool::poolSubmit@70 (line 2625)
; - java.util.concurrent.ForkJoinPool::submit@51 (line 3241)
; - java.util.concurrent.ForkJoinPool::submit@2 (line 200)
Due to this induced CAS contention on the "ctl" field, all other places where "clt" is accessed take an additional 41% of CPU cycles in the virtual thread case. In the platform FJP case, the cost of additional access to "ctl" is ~2.4% of CPU cycles.
It was found that the behavior difference can be explained by wrapping actions into AdaptedRunnable or AdaptedInterruptibleRunnable ForkJoinTasks.
For submitting from external threads, AdaptedInterruptibleRunnable is used.
InterruptibleRunnable has significantly less signalWork impact than AdaptedRunnable.
The simplest way to recheck this is to run the platform FJP benchmark, and perform the submit operation from the other FJP pool. Running it in such a way, from the FJP thread, the AdaptedRunnable wrapper is used, but since the other FJP is used, the submit stays interpreted as an external submit.
Here is the chart, and the platform FJP benchmark with AdaptedRunnable behaves the same way as virtual threads.
- causes
-
-

- Closed
-
- duplicates
-
-

- Closed
-
- links to
-
 Commit(master)
openjdk/jdk/fd7283be
Commit(master)
openjdk/jdk/fd7283be
-
 Review(master)
openjdk/jdk/26479
Review(master)
openjdk/jdk/26479