-
Type:
Enhancement
-
Resolution: Unresolved
-
Priority:
 P4
P4
-
Affects Version/s: 26
-
Component/s: hotspot
C2 SuperWord does currently not at all allow Object array accesses.
I started thinking about this during JVMLS 2025.
So far, I've identified these challenges:
- If the Load/Store have GC barriers, that can increase the body_size and prevent unrolling.
- We might need vectorized versions of Load/Store with GC barrier.
- With the current limitations of C2 SuperWord, we may only be able to vectorize fill and copy patterns. Anything beyond that would probably require if-conversion (null-check, subtype-check) and gather/scatter (dereference pointer and load field values in a vectorized way).
------------------------------------
I think it could be quite profitable. See this initial experiment of an array copy:
jdk-26-ea+5/bin/java -XX:CompileCommand=compileonly,Test::copy* -XX:CompileCommand=printcompilation,Test::copy* -Xbatch Test.java
CompileCommand: compileonly Test.copy* bool compileonly = true
CompileCommand: PrintCompilation Test.copy* bool PrintCompilation = true
Warmup
1421 99 % b 3 Test::copy_A1 @ 2 (21 bytes)
1422 100 b 3 Test::copy_A1 (21 bytes)
1423 101 % b 4 Test::copy_A1 @ 2 (21 bytes)
1426 102 b 4 Test::copy_A1 (21 bytes)
Run
elapsed: 6.4033327
Warmup
9123 107 b 3 Test::copy_A2 (10 bytes)
9184 108 b 4 Test::copy_A2 (10 bytes)
Run
elapsed: 0.58475024
The A1 variant is a regular Java loop, the A2 does System.arraycopy, so it is fully intrinsified (with vectorization).
But when I run it with GraalJIT, the A1 version is even faster!
jdk-26-ea+5/bin/java -XX:CompileCommand=compileonly,Test::copy* -XX:CompileCommand=printcompilation,Test::copy* -Xbatch -XX:+UnlockExperimentalVMOptions -XX:+UseGraalJIT Test.java
CompileCommand: compileonly Test.copy* bool compileonly = true
CompileCommand: PrintCompilation Test.copy* bool PrintCompilation = true
Warmup
1416 99 % b 3 Test::copy_A1 @ 2 (21 bytes)
1416 100 b 3 Test::copy_A1 (21 bytes)
1417 101 % b 4 Test::copy_A1 @ 2 (21 bytes)
1433 102 b 4 Test::copy_A1 (21 bytes)
Run
elapsed: 0.5728119
Warmup
2140 107 b 3 Test::copy_A2 (10 bytes)
2201 108 b 4 Test::copy_A2 (10 bytes)
Run
elapsed: 0.71295345
----------------------------------
I'm not sure how easy this task would be in C2 SuperWord. We would have to also see how it deals with GC barriers.
We also probably cannot do much more than fill and copy.
- fill: only requires a store of a given (loop invariant) pointer. So only a StoreN/StoreP would need to be vectorized.
- copy: only LoadN/P and StoreN/P.
For anything more advanced, we'd need if-conversion (null-check, subtype-check), and maybe even gather/scatter (dereference pointers, gather fields). I don't know if that would be possible and profitable.
Example:
- reduction over fields: LoadN/P from array, then null-check (maybe implicit or explicit), then vectorized dereference / field load. Would require if-conversion for the check and field-gather.
------------------------------
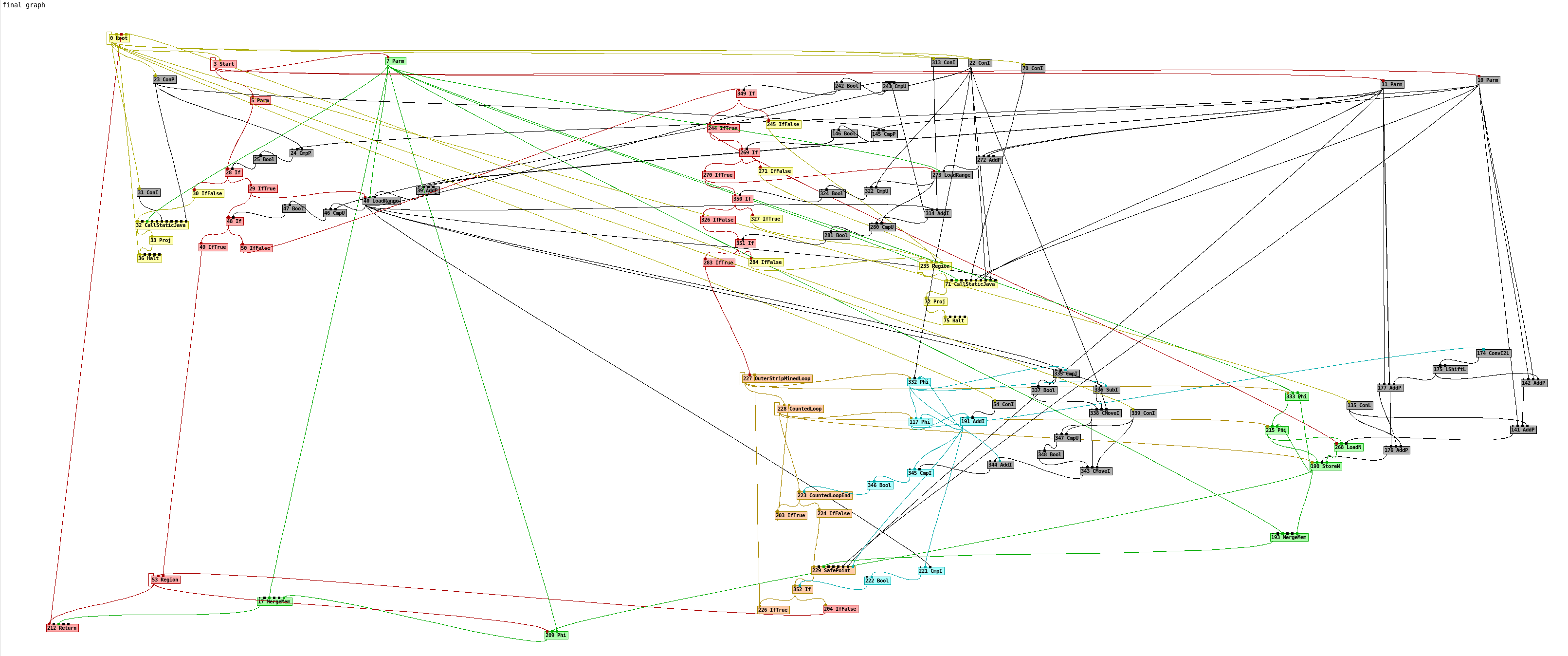
A quick visualization of the C2-copy_A1-graph.png shows that no control flow remains, we just have a LoadN and a StoreN. At least with G1GC. Also: no unrolling. Strange!
ZGC produces a different graph... we do some unrolling and using LoadP / StoreP. Weird! Even that could produce quite different results in performance, not even due to GC!
Probably, the difference is due to narrow/full-pointer.
----------------------- Performance numbers with ZGC ------------------
jdk-26-ea+5/bin/java -XX:CompileCommand=compileonly,Test::copy* -XX:CompileCommand=printcompilation,Test::copy* -Xbatch -XX:+UseZGC Test.java
CompileCommand: compileonly Test.copy* bool compileonly = true
CompileCommand: PrintCompilation Test.copy* bool PrintCompilation = true
Warmup
1561 99 % b 3 Test::copy_A1 @ 2 (21 bytes)
1562 100 b 3 Test::copy_A1 (21 bytes)
1563 101 % b 4 Test::copy_A1 @ 2 (21 bytes)
1568 102 b 4 Test::copy_A1 (21 bytes)
Run
elapsed: 4.695262
Warmup
7288 107 b 3 Test::copy_A2 (10 bytes)
7569 108 b 4 Test::copy_A2 (10 bytes)
Run
elapsed: 2.7455864
Very interesting, the difference is now much smaller. I suspect that unrolling did a great trick, and somehow System.arraycopy is not as fast here. It is not just half as fast because it accesses double as much memory, but much slower.
Not sure if this is a valid config, but GraalJIT with ZGC is doing worse:
jdk-26-ea+5/bin/java -XX:CompileCommand=compileonly,Test::copy* -XX:CompileCommand=printcompilation,Test::copy* -Xbatch -XX:+UnlockExperimentalVMOptions -XX:+UseGraalJIT -XX:+UseZGC Test.java
CompileCommand: compileonly Test.copy* bool compileonly = true
CompileCommand: PrintCompilation Test.copy* bool PrintCompilation = true
Warmup
1518 99 % b 3 Test::copy_A1 @ 2 (21 bytes)
1519 100 b 3 Test::copy_A1 (21 bytes)
1519 101 % b 4 Test::copy_A1 @ 2 (21 bytes)
1533 102 b 4 Test::copy_A1 (21 bytes)
Run
elapsed: 6.261946
Warmup
9109 107 b 3 Test::copy_A2 (10 bytes)
9394 108 b 4 Test::copy_A2 (10 bytes)
Run
elapsed: 5.7033596
----------------------------------------
Now Let's look at the backend of those pointer loads and stores. I'll focus on x64.
4349 // Load Compressed Pointer
4350 instruct loadN(rRegN dst, memory mem)
4351 %{
4352 predicate(n->as_Load()->barrier_data() == 0);
4353 match(Set dst (LoadN mem));
4354
4355 ins_cost(125); // XXX
4356 format %{ "movl $dst, $mem\t# compressed ptr" %}
4357 ins_encode %{
4358 __ movl($dst$$Register, $mem$$Address);
4359 %}
4360 ins_pipe(ialu_reg_mem); // XXX
4361 %}
5212 // Store Compressed Pointer
5213 instruct storeN(memory mem, rRegN src)
5214 %{
5215 predicate(n->as_Store()->barrier_data() == 0);
5216 match(Set mem (StoreN mem src));
5217
5218 ins_cost(125); // XXX
5219 format %{ "movl $mem, $src\t# compressed ptr" %}
5220 ins_encode %{
5221 __ movl($mem$$Address, $src$$Register);
5222 %}
5223 ins_pipe(ialu_mem_reg);
5224 %}
Ok, so it seems that simple LoadN / StoreN just do mem/reg moves.
Sadly, those require that we have no GC barriers, and we probably do need GC barriers here.
It looks like LoadP / StoreP are similar.
4335 // Load Pointer
4336 instruct loadP(rRegP dst, memory mem)
4337 %{
4338 match(Set dst (LoadP mem));
4339 predicate(n->as_Load()->barrier_data() == 0);
4340
4341 ins_cost(125); // XXX
4342 format %{ "movq $dst, $mem\t# ptr" %}
4343 ins_encode %{
4344 __ movq($dst$$Register, $mem$$Address);
4345 %}
4346 ins_pipe(ialu_reg_mem); // XXX
4347 %}
5171 // Store Pointer
5172 instruct storeP(memory mem, any_RegP src)
5173 %{
5174 predicate(n->as_Store()->barrier_data() == 0);
5175 match(Set mem (StoreP mem src));
5176
5177 ins_cost(125); // XXX
5178 format %{ "movq $mem, $src\t# ptr" %}
5179 ins_encode %{
5180 __ movq($mem$$Address, $src$$Register);
5181 %}
5182 ins_pipe(ialu_mem_reg);
5183 %}
------------------------------
Let's also quickly investigate why we unroll the copy_A1 loop with ZGC, but not with G1GC.
ZGC:
Counted Loop: N226/N201 counted [0,int),+1 (-1 iters)
Loop: N0/N0 has_sfpt
Loop: N225/N224 limit_check short_running profile_predicated predicated
Loop: N226/N201 limit_check short_running profile_predicated predicated counted [0,int),+1 (-1 iters) has_sfpt strip_mined
Predicate RC Loop: N226/N201 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt rce strip_mined
Predicate IC Loop: N226/N201 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt rce strip_mined
Predicate RC Loop: N226/N201 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt rce strip_mined
Loop: N0/N0 has_sfpt
Loop: N225/N224 limit_check short_running profile_predicated predicated sfpts={ 227 }
Loop: N226/N201 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt strip_mined
PreMainPost Loop: N226/N201 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt strip_mined
Unroll 2 Loop: N226/N201 limit_check counted [int,int),+1 (40920 iters) main has_sfpt strip_mined
...
Loop: N0/N0 has_sfpt
Loop: N453/N458 predicated counted [0,int),+1 (4 iters) pre
Loop: N225/N224 limit_check sfpts={ 227 }
Loop: N803/N201 limit_check counted [int,int),+8 (40920 iters) main has_sfpt strip_mined
Loop: N338/N343 limit_check counted [int,int),+1 (4 iters) post
G1GC:
Counted Loop: N228/N203 counted [0,int),+1 (-1 iters)
Loop: N0/N0 has_sfpt
Loop: N227/N226 limit_check short_running profile_predicated predicated
Loop: N228/N203 limit_check short_running profile_predicated predicated counted [0,int),+1 (-1 iters) has_sfpt strip_mined
Predicate RC Loop: N228/N203 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt rce strip_mined
Predicate IC Loop: N228/N203 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt rce strip_mined
Predicate RC Loop: N228/N203 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt rce strip_mined
Loop: N0/N0 has_sfpt
Loop: N227/N226 limit_check short_running profile_predicated predicated sfpts={ 229 }
Loop: N228/N203 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt strip_mined
...
Loop: N0/N0 has_sfpt
Loop: N227/N226 limit_check predicated sfpts={ 229 }
Loop: N228/N203 limit_check predicated counted [0,int),+1 (40920 iters) has_sfpt strip_mined
It seems with G1GC we don't want to do PreMainPost nor Unroll.
Ah, we seem to bail out here:
1141 // Check for being too big
1142 if (body_size > (uint)_local_loop_unroll_limit) {
1143 if ((cl->is_subword_loop() || xors_in_loop >= 4) && body_size < 4u * LoopUnrollLimit) {
1144 return should_unroll && phase->may_require_nodes(estimate);
1145 }
1146 return false; // Loop too big.
1147 }
We have body_size == 82
But the body is quite small actually:
(rr) p _body.dump()
0--> 222 Bool === _ 221 [[ 223 ]] [lt] !orig=[201] !jvms: Test::copy_A1 @ bci:5 (line 38)
1--> 221 CmpI === _ 191 40 [[ 222 ]] !orig=[200] !jvms: Test::copy_A1 @ bci:5 (line 38)
2--> 191 AddI === _ 117 54 [[ 229 221 117 ]] !orig=[220],... !jvms: Test::copy_A1 @ bci:14 (line 38)
3--> 190 StoreN === 228 215 176 268 [[ 209 193 215 ]] @narrowoop: java/lang/Object *[int:>=0] (java/lang/Cloneable,java/io/Serializable)+any * [narrow], idx=5; Memory: @narrowoop: Test$A *[int:>=0] (java/lang/Cloneable,java/io/Serializable):NotNull+any * [narrow], idx=5; !jvms: Test::copy_A1 @ bci:13 (line 39)
4--> 176 AddP === _ 157 177 135 [[ 190 ]] !jvms: Test::copy_A1 @ bci:13 (line 39)
5--> 268 LoadN === 266 215 141 [[ 190 ]] @narrowoop: java/lang/Object *[int:>=0] (java/lang/Cloneable,java/io/Serializable)+any * [narrow], idx=5; #narrowoop: Test$A * (does not depend only on test, unknown control) !orig=[143],[189] !jvms: Test::copy_A1 @ bci:12 (line 39)
6--> 141 AddP === _ 37 142 135 [[ 268 ]] !jvms: Test::copy_A1 @ bci:12 (line 39)
7--> 177 AddP === _ 157 157 175 [[ 176 ]] !jvms: Test::copy_A1 @ bci:13 (line 39)
8--> 142 AddP === _ 37 37 175 [[ 141 ]] !jvms: Test::copy_A1 @ bci:12 (line 39)
9--> 175 LShiftL === _ 174 139 [[ 177 142 ]] !orig=[140] !jvms: Test::copy_A1 @ bci:13 (line 39)
10--> 228 CountedLoop === 228 227 203 [[ 228 223 117 215 190 ]] inner stride: 1 strip mined !orig=[219],[114] !jvms: Test::copy_A1 @ bci:8 (line 39)
11--> 215 Phi === 228 7 190 [[ 190 268 ]] #memory Memory: @narrowoop: java/lang/Object *[int:>=0] (java/lang/Cloneable,java/io/Serializable)+any * [narrow], idx=5; !orig=[213],[116] !jvms: Test::copy_A1 @ bci:8 (line 39)
12--> 174 ConvI2L === _ 117 [[ 175 ]] #long:0..maxint-1, widen: 3 !orig=[138] !jvms: Test::copy_A1 @ bci:13 (line 39)
13--> 117 Phi === 228 22 191 [[ 174 191 ]] #int:0..maxint-1, widen: 3 #tripcount !orig=[306],[173] !jvms: Test::copy_A1 @ bci:8 (line 39)
14--> 223 CountedLoopEnd === 228 222 [[ 224 203 ]] [lt] P=0.999976, C=81918.000000 !orig=[202] !jvms: Test::copy_A1 @ bci:5 (line 38)
15--> 203 IfTrue === 223 [[ 228 ]] #1 !jvms: Test::copy_A1 @ bci:5 (line 38)
The body_size starts at the 16. Ah ok. but "190 StoreN" apparently adds 66 because of the estimated_barrier_size. Interesting!
That immediately prevents unrolling, since the unroll limit is at 60 nodes.
Hmm, does that also affect our prospects with vectorization? Probably. This is probably expanded in late barrier expansion. Hmm. I'll have to investigate what happens there. I suppose ZGC must have lower barrier size so that we can get unrolling.
As a quick experiment: let's increase the node limit for unrolling with G1GC, and see if that would get better performance.
And -XX:LoopUnrollLimit=200 would allow unrolling, it changed the performance from 7.003714 to only 6.78395. Not much. But it is measurably better.
---------------------------------
Ok, now I tracked the StoreN down to g1StoreN.
104 instruct g1StoreN(memory mem, rRegN src, rRegP tmp1, rRegP tmp2, rRegP tmp3, rFlagsReg cr)
105 %{
106 predicate(UseG1GC && n->as_Store()->barrier_data() != 0);
107 match(Set mem (StoreN mem src));
108 effect(TEMP tmp1, TEMP tmp2, TEMP tmp3, KILL cr);
109 ins_cost(125); // XXX
110 format %{ "movl $mem, $src\t# ptr" %}
111 ins_encode %{
112 __ lea($tmp1$$Register, $mem$$Address);
113 write_barrier_pre(masm, this,
114 $tmp1$$Register /* obj */,
115 $tmp2$$Register /* pre_val */,
116 $tmp3$$Register /* tmp */,
117 RegSet::of($tmp1$$Register, $src$$Register) /* preserve */);
118 __ movl(Address($tmp1$$Register, 0), $src$$Register);
119 if ((barrier_data() & G1C2BarrierPost) != 0) {
120 __ movl($tmp2$$Register, $src$$Register);
121 if ((barrier_data() & G1C2BarrierPostNotNull) == 0) {
122 __ decode_heap_oop($tmp2$$Register);
123 } else {
124 __ decode_heap_oop_not_null($tmp2$$Register);
125 }
126 }
127 write_barrier_post(masm, this,
128 $tmp1$$Register /* store_addr */,
129 $tmp2$$Register /* new_val */,
130 $tmp3$$Register /* tmp1 */,
131 $tmp2$$Register /* tmp2 */);
132 %}
133 ins_pipe(ialu_mem_reg);
134 %}
I see, this generates a lot of code. That explains the extra body_size. Though I do wonder if it is tuned right, i.e. if we really intended to prevent unrolling with it. After all it does not take up C2 nodes. It does take up code space in the loop though. However, the slow-path does not have to be located inside the loop.
I also wonder if this could have a vectorized alternative of these Loads/Stores with GC barriers.
How I imagine that:
- LoadVector(N/P) loads the bytes. Then a vectorized check if we need to take the slow-path. I'd hope that in most cases, the slow-path is very very rare, and so most of the time all lanes would report that we can take the fast-path. The fast-path should be easy to vectorize. In the slow-path, we could at first just scalarize, i.e. extract all lanes and pack them again. As long as this is rare, this would be a minimal overhead that we can more than win back by the vectorization of the fast-path.
I started thinking about this during JVMLS 2025.
So far, I've identified these challenges:
- If the Load/Store have GC barriers, that can increase the body_size and prevent unrolling.
- We might need vectorized versions of Load/Store with GC barrier.
- With the current limitations of C2 SuperWord, we may only be able to vectorize fill and copy patterns. Anything beyond that would probably require if-conversion (null-check, subtype-check) and gather/scatter (dereference pointer and load field values in a vectorized way).
------------------------------------
I think it could be quite profitable. See this initial experiment of an array copy:
jdk-26-ea+5/bin/java -XX:CompileCommand=compileonly,Test::copy* -XX:CompileCommand=printcompilation,Test::copy* -Xbatch Test.java
CompileCommand: compileonly Test.copy* bool compileonly = true
CompileCommand: PrintCompilation Test.copy* bool PrintCompilation = true
Warmup
1421 99 % b 3 Test::copy_A1 @ 2 (21 bytes)
1422 100 b 3 Test::copy_A1 (21 bytes)
1423 101 % b 4 Test::copy_A1 @ 2 (21 bytes)
1426 102 b 4 Test::copy_A1 (21 bytes)
Run
elapsed: 6.4033327
Warmup
9123 107 b 3 Test::copy_A2 (10 bytes)
9184 108 b 4 Test::copy_A2 (10 bytes)
Run
elapsed: 0.58475024
The A1 variant is a regular Java loop, the A2 does System.arraycopy, so it is fully intrinsified (with vectorization).
But when I run it with GraalJIT, the A1 version is even faster!
jdk-26-ea+5/bin/java -XX:CompileCommand=compileonly,Test::copy* -XX:CompileCommand=printcompilation,Test::copy* -Xbatch -XX:+UnlockExperimentalVMOptions -XX:+UseGraalJIT Test.java
CompileCommand: compileonly Test.copy* bool compileonly = true
CompileCommand: PrintCompilation Test.copy* bool PrintCompilation = true
Warmup
1416 99 % b 3 Test::copy_A1 @ 2 (21 bytes)
1416 100 b 3 Test::copy_A1 (21 bytes)
1417 101 % b 4 Test::copy_A1 @ 2 (21 bytes)
1433 102 b 4 Test::copy_A1 (21 bytes)
Run
elapsed: 0.5728119
Warmup
2140 107 b 3 Test::copy_A2 (10 bytes)
2201 108 b 4 Test::copy_A2 (10 bytes)
Run
elapsed: 0.71295345
----------------------------------
I'm not sure how easy this task would be in C2 SuperWord. We would have to also see how it deals with GC barriers.
We also probably cannot do much more than fill and copy.
- fill: only requires a store of a given (loop invariant) pointer. So only a StoreN/StoreP would need to be vectorized.
- copy: only LoadN/P and StoreN/P.
For anything more advanced, we'd need if-conversion (null-check, subtype-check), and maybe even gather/scatter (dereference pointers, gather fields). I don't know if that would be possible and profitable.
Example:
- reduction over fields: LoadN/P from array, then null-check (maybe implicit or explicit), then vectorized dereference / field load. Would require if-conversion for the check and field-gather.
------------------------------
A quick visualization of the C2-copy_A1-graph.png shows that no control flow remains, we just have a LoadN and a StoreN. At least with G1GC. Also: no unrolling. Strange!
ZGC produces a different graph... we do some unrolling and using LoadP / StoreP. Weird! Even that could produce quite different results in performance, not even due to GC!
Probably, the difference is due to narrow/full-pointer.
----------------------- Performance numbers with ZGC ------------------
jdk-26-ea+5/bin/java -XX:CompileCommand=compileonly,Test::copy* -XX:CompileCommand=printcompilation,Test::copy* -Xbatch -XX:+UseZGC Test.java
CompileCommand: compileonly Test.copy* bool compileonly = true
CompileCommand: PrintCompilation Test.copy* bool PrintCompilation = true
Warmup
1561 99 % b 3 Test::copy_A1 @ 2 (21 bytes)
1562 100 b 3 Test::copy_A1 (21 bytes)
1563 101 % b 4 Test::copy_A1 @ 2 (21 bytes)
1568 102 b 4 Test::copy_A1 (21 bytes)
Run
elapsed: 4.695262
Warmup
7288 107 b 3 Test::copy_A2 (10 bytes)
7569 108 b 4 Test::copy_A2 (10 bytes)
Run
elapsed: 2.7455864
Very interesting, the difference is now much smaller. I suspect that unrolling did a great trick, and somehow System.arraycopy is not as fast here. It is not just half as fast because it accesses double as much memory, but much slower.
Not sure if this is a valid config, but GraalJIT with ZGC is doing worse:
jdk-26-ea+5/bin/java -XX:CompileCommand=compileonly,Test::copy* -XX:CompileCommand=printcompilation,Test::copy* -Xbatch -XX:+UnlockExperimentalVMOptions -XX:+UseGraalJIT -XX:+UseZGC Test.java
CompileCommand: compileonly Test.copy* bool compileonly = true
CompileCommand: PrintCompilation Test.copy* bool PrintCompilation = true
Warmup
1518 99 % b 3 Test::copy_A1 @ 2 (21 bytes)
1519 100 b 3 Test::copy_A1 (21 bytes)
1519 101 % b 4 Test::copy_A1 @ 2 (21 bytes)
1533 102 b 4 Test::copy_A1 (21 bytes)
Run
elapsed: 6.261946
Warmup
9109 107 b 3 Test::copy_A2 (10 bytes)
9394 108 b 4 Test::copy_A2 (10 bytes)
Run
elapsed: 5.7033596
----------------------------------------
Now Let's look at the backend of those pointer loads and stores. I'll focus on x64.
4349 // Load Compressed Pointer
4350 instruct loadN(rRegN dst, memory mem)
4351 %{
4352 predicate(n->as_Load()->barrier_data() == 0);
4353 match(Set dst (LoadN mem));
4354
4355 ins_cost(125); // XXX
4356 format %{ "movl $dst, $mem\t# compressed ptr" %}
4357 ins_encode %{
4358 __ movl($dst$$Register, $mem$$Address);
4359 %}
4360 ins_pipe(ialu_reg_mem); // XXX
4361 %}
5212 // Store Compressed Pointer
5213 instruct storeN(memory mem, rRegN src)
5214 %{
5215 predicate(n->as_Store()->barrier_data() == 0);
5216 match(Set mem (StoreN mem src));
5217
5218 ins_cost(125); // XXX
5219 format %{ "movl $mem, $src\t# compressed ptr" %}
5220 ins_encode %{
5221 __ movl($mem$$Address, $src$$Register);
5222 %}
5223 ins_pipe(ialu_mem_reg);
5224 %}
Ok, so it seems that simple LoadN / StoreN just do mem/reg moves.
Sadly, those require that we have no GC barriers, and we probably do need GC barriers here.
It looks like LoadP / StoreP are similar.
4335 // Load Pointer
4336 instruct loadP(rRegP dst, memory mem)
4337 %{
4338 match(Set dst (LoadP mem));
4339 predicate(n->as_Load()->barrier_data() == 0);
4340
4341 ins_cost(125); // XXX
4342 format %{ "movq $dst, $mem\t# ptr" %}
4343 ins_encode %{
4344 __ movq($dst$$Register, $mem$$Address);
4345 %}
4346 ins_pipe(ialu_reg_mem); // XXX
4347 %}
5171 // Store Pointer
5172 instruct storeP(memory mem, any_RegP src)
5173 %{
5174 predicate(n->as_Store()->barrier_data() == 0);
5175 match(Set mem (StoreP mem src));
5176
5177 ins_cost(125); // XXX
5178 format %{ "movq $mem, $src\t# ptr" %}
5179 ins_encode %{
5180 __ movq($mem$$Address, $src$$Register);
5181 %}
5182 ins_pipe(ialu_mem_reg);
5183 %}
------------------------------
Let's also quickly investigate why we unroll the copy_A1 loop with ZGC, but not with G1GC.
ZGC:
Counted Loop: N226/N201 counted [0,int),+1 (-1 iters)
Loop: N0/N0 has_sfpt
Loop: N225/N224 limit_check short_running profile_predicated predicated
Loop: N226/N201 limit_check short_running profile_predicated predicated counted [0,int),+1 (-1 iters) has_sfpt strip_mined
Predicate RC Loop: N226/N201 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt rce strip_mined
Predicate IC Loop: N226/N201 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt rce strip_mined
Predicate RC Loop: N226/N201 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt rce strip_mined
Loop: N0/N0 has_sfpt
Loop: N225/N224 limit_check short_running profile_predicated predicated sfpts={ 227 }
Loop: N226/N201 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt strip_mined
PreMainPost Loop: N226/N201 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt strip_mined
Unroll 2 Loop: N226/N201 limit_check counted [int,int),+1 (40920 iters) main has_sfpt strip_mined
...
Loop: N0/N0 has_sfpt
Loop: N453/N458 predicated counted [0,int),+1 (4 iters) pre
Loop: N225/N224 limit_check sfpts={ 227 }
Loop: N803/N201 limit_check counted [int,int),+8 (40920 iters) main has_sfpt strip_mined
Loop: N338/N343 limit_check counted [int,int),+1 (4 iters) post
G1GC:
Counted Loop: N228/N203 counted [0,int),+1 (-1 iters)
Loop: N0/N0 has_sfpt
Loop: N227/N226 limit_check short_running profile_predicated predicated
Loop: N228/N203 limit_check short_running profile_predicated predicated counted [0,int),+1 (-1 iters) has_sfpt strip_mined
Predicate RC Loop: N228/N203 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt rce strip_mined
Predicate IC Loop: N228/N203 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt rce strip_mined
Predicate RC Loop: N228/N203 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt rce strip_mined
Loop: N0/N0 has_sfpt
Loop: N227/N226 limit_check short_running profile_predicated predicated sfpts={ 229 }
Loop: N228/N203 limit_check short_running profile_predicated predicated counted [0,int),+1 (40920 iters) has_sfpt strip_mined
...
Loop: N0/N0 has_sfpt
Loop: N227/N226 limit_check predicated sfpts={ 229 }
Loop: N228/N203 limit_check predicated counted [0,int),+1 (40920 iters) has_sfpt strip_mined
It seems with G1GC we don't want to do PreMainPost nor Unroll.
Ah, we seem to bail out here:
1141 // Check for being too big
1142 if (body_size > (uint)_local_loop_unroll_limit) {
1143 if ((cl->is_subword_loop() || xors_in_loop >= 4) && body_size < 4u * LoopUnrollLimit) {
1144 return should_unroll && phase->may_require_nodes(estimate);
1145 }
1146 return false; // Loop too big.
1147 }
We have body_size == 82
But the body is quite small actually:
(rr) p _body.dump()
0--> 222 Bool === _ 221 [[ 223 ]] [lt] !orig=[201] !jvms: Test::copy_A1 @ bci:5 (line 38)
1--> 221 CmpI === _ 191 40 [[ 222 ]] !orig=[200] !jvms: Test::copy_A1 @ bci:5 (line 38)
2--> 191 AddI === _ 117 54 [[ 229 221 117 ]] !orig=[220],... !jvms: Test::copy_A1 @ bci:14 (line 38)
3--> 190 StoreN === 228 215 176 268 [[ 209 193 215 ]] @narrowoop: java/lang/Object *[int:>=0] (java/lang/Cloneable,java/io/Serializable)+any * [narrow], idx=5; Memory: @narrowoop: Test$A *[int:>=0] (java/lang/Cloneable,java/io/Serializable):NotNull+any * [narrow], idx=5; !jvms: Test::copy_A1 @ bci:13 (line 39)
4--> 176 AddP === _ 157 177 135 [[ 190 ]] !jvms: Test::copy_A1 @ bci:13 (line 39)
5--> 268 LoadN === 266 215 141 [[ 190 ]] @narrowoop: java/lang/Object *[int:>=0] (java/lang/Cloneable,java/io/Serializable)+any * [narrow], idx=5; #narrowoop: Test$A * (does not depend only on test, unknown control) !orig=[143],[189] !jvms: Test::copy_A1 @ bci:12 (line 39)
6--> 141 AddP === _ 37 142 135 [[ 268 ]] !jvms: Test::copy_A1 @ bci:12 (line 39)
7--> 177 AddP === _ 157 157 175 [[ 176 ]] !jvms: Test::copy_A1 @ bci:13 (line 39)
8--> 142 AddP === _ 37 37 175 [[ 141 ]] !jvms: Test::copy_A1 @ bci:12 (line 39)
9--> 175 LShiftL === _ 174 139 [[ 177 142 ]] !orig=[140] !jvms: Test::copy_A1 @ bci:13 (line 39)
10--> 228 CountedLoop === 228 227 203 [[ 228 223 117 215 190 ]] inner stride: 1 strip mined !orig=[219],[114] !jvms: Test::copy_A1 @ bci:8 (line 39)
11--> 215 Phi === 228 7 190 [[ 190 268 ]] #memory Memory: @narrowoop: java/lang/Object *[int:>=0] (java/lang/Cloneable,java/io/Serializable)+any * [narrow], idx=5; !orig=[213],[116] !jvms: Test::copy_A1 @ bci:8 (line 39)
12--> 174 ConvI2L === _ 117 [[ 175 ]] #long:0..maxint-1, widen: 3 !orig=[138] !jvms: Test::copy_A1 @ bci:13 (line 39)
13--> 117 Phi === 228 22 191 [[ 174 191 ]] #int:0..maxint-1, widen: 3 #tripcount !orig=[306],[173] !jvms: Test::copy_A1 @ bci:8 (line 39)
14--> 223 CountedLoopEnd === 228 222 [[ 224 203 ]] [lt] P=0.999976, C=81918.000000 !orig=[202] !jvms: Test::copy_A1 @ bci:5 (line 38)
15--> 203 IfTrue === 223 [[ 228 ]] #1 !jvms: Test::copy_A1 @ bci:5 (line 38)
The body_size starts at the 16. Ah ok. but "190 StoreN" apparently adds 66 because of the estimated_barrier_size. Interesting!
That immediately prevents unrolling, since the unroll limit is at 60 nodes.
Hmm, does that also affect our prospects with vectorization? Probably. This is probably expanded in late barrier expansion. Hmm. I'll have to investigate what happens there. I suppose ZGC must have lower barrier size so that we can get unrolling.
As a quick experiment: let's increase the node limit for unrolling with G1GC, and see if that would get better performance.
And -XX:LoopUnrollLimit=200 would allow unrolling, it changed the performance from 7.003714 to only 6.78395. Not much. But it is measurably better.
---------------------------------
Ok, now I tracked the StoreN down to g1StoreN.
104 instruct g1StoreN(memory mem, rRegN src, rRegP tmp1, rRegP tmp2, rRegP tmp3, rFlagsReg cr)
105 %{
106 predicate(UseG1GC && n->as_Store()->barrier_data() != 0);
107 match(Set mem (StoreN mem src));
108 effect(TEMP tmp1, TEMP tmp2, TEMP tmp3, KILL cr);
109 ins_cost(125); // XXX
110 format %{ "movl $mem, $src\t# ptr" %}
111 ins_encode %{
112 __ lea($tmp1$$Register, $mem$$Address);
113 write_barrier_pre(masm, this,
114 $tmp1$$Register /* obj */,
115 $tmp2$$Register /* pre_val */,
116 $tmp3$$Register /* tmp */,
117 RegSet::of($tmp1$$Register, $src$$Register) /* preserve */);
118 __ movl(Address($tmp1$$Register, 0), $src$$Register);
119 if ((barrier_data() & G1C2BarrierPost) != 0) {
120 __ movl($tmp2$$Register, $src$$Register);
121 if ((barrier_data() & G1C2BarrierPostNotNull) == 0) {
122 __ decode_heap_oop($tmp2$$Register);
123 } else {
124 __ decode_heap_oop_not_null($tmp2$$Register);
125 }
126 }
127 write_barrier_post(masm, this,
128 $tmp1$$Register /* store_addr */,
129 $tmp2$$Register /* new_val */,
130 $tmp3$$Register /* tmp1 */,
131 $tmp2$$Register /* tmp2 */);
132 %}
133 ins_pipe(ialu_mem_reg);
134 %}
I see, this generates a lot of code. That explains the extra body_size. Though I do wonder if it is tuned right, i.e. if we really intended to prevent unrolling with it. After all it does not take up C2 nodes. It does take up code space in the loop though. However, the slow-path does not have to be located inside the loop.
I also wonder if this could have a vectorized alternative of these Loads/Stores with GC barriers.
How I imagine that:
- LoadVector(N/P) loads the bytes. Then a vectorized check if we need to take the slow-path. I'd hope that in most cases, the slow-path is very very rare, and so most of the time all lanes would report that we can take the fast-path. The fast-path should be easy to vectorize. In the slow-path, we could at first just scalarize, i.e. extract all lanes and pack them again. As long as this is rare, this would be a minimal overhead that we can more than win back by the vectorization of the fast-path.
- relates to
-
-
- Open
-