-
Type:
Bug
-
Resolution: Unresolved
-
Priority:
 P4
P4
-
Affects Version/s: 25
-
Component/s: hotspot
As part of exploratory task JDK-8373026, I played with an array reverse benchmark.
I found this on my AVX512 machine. Did not yet investigate other platforms.
I noticed a 10% performance regression in JDK25:
[empeter@emanuel bin]$ ~/Documents/oracle/jdk-25-ea+2/bin/java -XX:CompileCommand=compileonly,Test*::test -XX:CompileCommand=printcompilation,Test*::* -Xbatch --add-modules=jdk.incubator.vector -XX:LoopMaxUnroll=0 TestReverse.java
CompileCommand: compileonly Test*.test bool compileonly = true
CompileCommand: PrintCompilation Test*.* bool PrintCompilation = true
WARNING: Using incubator modules: jdk.incubator.vector
Warmup
5569 101 % b 3 TestReverse::test @ 2 (69 bytes)
5570 102 b 3 TestReverse::test (69 bytes)
8145 103 % b 4 TestReverse::test @ 2 (69 bytes)
8149 104 b 4 TestReverse::test (69 bytes)
Benchmark
Elapsed: 3270637387
[empeter@emanuel bin]$ ~/Documents/oracle/jdk-25-ea+1/bin/java -XX:CompileCommand=compileonly,Test*::test -XX:CompileCommand=printcompilation,Test*::* -Xbatch --add-modules=jdk.incubator.vector -XX:LoopMaxUnroll=0 TestReverse.java
CompileCommand: compileonly Test*.test bool compileonly = true
CompileCommand: PrintCompilation Test*.* bool PrintCompilation = true
WARNING: Using incubator modules: jdk.incubator.vector
Warmup
5055 103 % b 3 TestReverse::test @ 2 (69 bytes)
5056 104 b 3 TestReverse::test (69 bytes)
7151 105 % b 4 TestReverse::test @ 2 (69 bytes)
7156 106 b 4 TestReverse::test (69 bytes)
Benchmark
Elapsed: 2932765433
The reason is that we have an extra LoadVector -> AndV in the loop.
With jdk-25-ea+1, it happens before the loop:
0x00007f752c1b2992: vmovdqu 0x10(%rcx),%xmm1
0x00007f752c1b2997: vpand %xmm0,%xmm1,%xmm0
0x00007f752c1b299b: vpmovzxbd %xmm0,%zmm0
0x00007f752c1b29a1: mov $0x1,%ebx
0x00007f752c1b29a6: mov %r10d,%ecx
0x00007f752c1b29a9: sub %ebx,%ecx
0x00007f752c1b29ab: cmp %ebx,%r10d
0x00007f752c1b29ae: cmovl %r8d,%ecx
0x00007f752c1b29b2: cmp $0x3e80,%ecx
0x00007f752c1b29b8: cmova %r11d,%ecx
0x00007f752c1b29bc: add %ebx,%ecx
0x00007f752c1b29be: xchg %ax,%ax
Loop:
0x00007f752c1b29c0: movslq %ebx,%rdi
0x00007f752c1b29c3: vmovdqu32 0x10(%rsi,%rdi,4),%zmm1
0x00007f752c1b29ce: vpermd %zmm1,%zmm0,%zmm1
0x00007f752c1b29d4: neg %rdi
0x00007f752c1b29d7: vmovdqu32 %zmm1,-0x30(%rdx,%rdi,4)
0x00007f752c1b29e2: add $0x10,%ebx
0x00007f752c1b29e5: cmp %ecx,%ebx
0x00007f752c1b29e7: jl 0x00007f752c1b29c0
But with jdk-25-ea+2:
0x00007f6d3c1b2313: mov $0x1,%edi
0x00007f6d3c1b2318: mov %r10d,%eax
0x00007f6d3c1b231b: sub %edi,%eax
0x00007f6d3c1b231d: cmp %edi,%r10d
0x00007f6d3c1b2320: cmovl %r9d,%eax
0x00007f6d3c1b2324: cmp $0x3e80,%eax
0x00007f6d3c1b2329: cmova %r8d,%eax
0x00007f6d3c1b232d: add %edi,%eax
0x00007f6d3c1b232f: nop
Loop:
0x00007f6d3c1b2330: vpandd 0x10(%rdx),%zmm0,%zmm1
0x00007f6d3c1b233a: movslq %edi,%r11
0x00007f6d3c1b233d: vmovdqu32 0x10(%rsi,%r11,4),%zmm2
0x00007f6d3c1b2348: vpermd %zmm2,%zmm1,%zmm1
0x00007f6d3c1b234e: neg %r11
0x00007f6d3c1b2351: vmovdqu32 %zmm1,-0x30(%rcx,%r11,4)
0x00007f6d3c1b235c: add $0x10,%edi
0x00007f6d3c1b235f: cmp %eax,%edi
0x00007f6d3c1b2361: jl 0x00007f6d3c1b2330
Specifically: we have this in the loop since then:
vpandd 0x10(%rdx),%zmm0,%zmm1
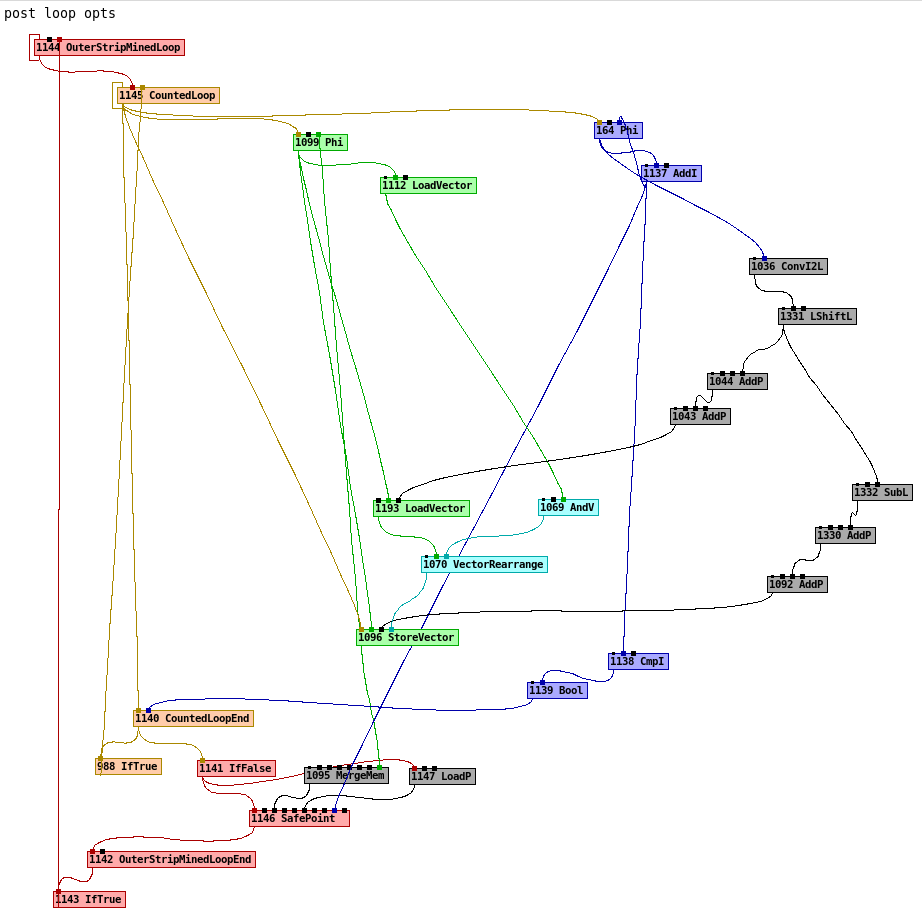
I also attached an image "C2_graph.png" that shows the C2 graph: it shows 2 LoadVector, and AndV a VectorRearrange and a StoreVector in the loop for JDK26. Before JDK25-ea+2, we would have had one less LoadVector and no AndV in the loop.
C2 does not let the LoadVector for the shuffle vector float out of the loop, because it is on the same int[] slice as the vector load/store from the arrays we are reversing. C2 can at that point not prove that the arrays do not alias.
------------------------------------------------------
I then did some digging into what changes went into jdk-25-ea+2, andJDK-8310691 is a reasonable candidate.
Another note: we should make sure we have better regression tests for these cases. But this is tricky, since the simple IR node counting does not work here. We'd need some way to tell if nodes are in the loop or not (e.g. 1 LoadVector and 0 AndV in loop).
---------------------------------------------------
Note: I only saw a 10% regression with -XX:LoopMaxUnroll=0. I think with sufficient unrolling the cost of the additional instruction is somehow hidden. Still, we should fix this, it is suboptimal to have extra instructions in the loop, and could show on other benchmarks down the line.
I found this on my AVX512 machine. Did not yet investigate other platforms.
I noticed a 10% performance regression in JDK25:
[empeter@emanuel bin]$ ~/Documents/oracle/jdk-25-ea+2/bin/java -XX:CompileCommand=compileonly,Test*::test -XX:CompileCommand=printcompilation,Test*::* -Xbatch --add-modules=jdk.incubator.vector -XX:LoopMaxUnroll=0 TestReverse.java
CompileCommand: compileonly Test*.test bool compileonly = true
CompileCommand: PrintCompilation Test*.* bool PrintCompilation = true
WARNING: Using incubator modules: jdk.incubator.vector
Warmup
5569 101 % b 3 TestReverse::test @ 2 (69 bytes)
5570 102 b 3 TestReverse::test (69 bytes)
8145 103 % b 4 TestReverse::test @ 2 (69 bytes)
8149 104 b 4 TestReverse::test (69 bytes)
Benchmark
Elapsed: 3270637387
[empeter@emanuel bin]$ ~/Documents/oracle/jdk-25-ea+1/bin/java -XX:CompileCommand=compileonly,Test*::test -XX:CompileCommand=printcompilation,Test*::* -Xbatch --add-modules=jdk.incubator.vector -XX:LoopMaxUnroll=0 TestReverse.java
CompileCommand: compileonly Test*.test bool compileonly = true
CompileCommand: PrintCompilation Test*.* bool PrintCompilation = true
WARNING: Using incubator modules: jdk.incubator.vector
Warmup
5055 103 % b 3 TestReverse::test @ 2 (69 bytes)
5056 104 b 3 TestReverse::test (69 bytes)
7151 105 % b 4 TestReverse::test @ 2 (69 bytes)
7156 106 b 4 TestReverse::test (69 bytes)
Benchmark
Elapsed: 2932765433
The reason is that we have an extra LoadVector -> AndV in the loop.
With jdk-25-ea+1, it happens before the loop:
0x00007f752c1b2992: vmovdqu 0x10(%rcx),%xmm1
0x00007f752c1b2997: vpand %xmm0,%xmm1,%xmm0
0x00007f752c1b299b: vpmovzxbd %xmm0,%zmm0
0x00007f752c1b29a1: mov $0x1,%ebx
0x00007f752c1b29a6: mov %r10d,%ecx
0x00007f752c1b29a9: sub %ebx,%ecx
0x00007f752c1b29ab: cmp %ebx,%r10d
0x00007f752c1b29ae: cmovl %r8d,%ecx
0x00007f752c1b29b2: cmp $0x3e80,%ecx
0x00007f752c1b29b8: cmova %r11d,%ecx
0x00007f752c1b29bc: add %ebx,%ecx
0x00007f752c1b29be: xchg %ax,%ax
Loop:
0x00007f752c1b29c0: movslq %ebx,%rdi
0x00007f752c1b29c3: vmovdqu32 0x10(%rsi,%rdi,4),%zmm1
0x00007f752c1b29ce: vpermd %zmm1,%zmm0,%zmm1
0x00007f752c1b29d4: neg %rdi
0x00007f752c1b29d7: vmovdqu32 %zmm1,-0x30(%rdx,%rdi,4)
0x00007f752c1b29e2: add $0x10,%ebx
0x00007f752c1b29e5: cmp %ecx,%ebx
0x00007f752c1b29e7: jl 0x00007f752c1b29c0
But with jdk-25-ea+2:
0x00007f6d3c1b2313: mov $0x1,%edi
0x00007f6d3c1b2318: mov %r10d,%eax
0x00007f6d3c1b231b: sub %edi,%eax
0x00007f6d3c1b231d: cmp %edi,%r10d
0x00007f6d3c1b2320: cmovl %r9d,%eax
0x00007f6d3c1b2324: cmp $0x3e80,%eax
0x00007f6d3c1b2329: cmova %r8d,%eax
0x00007f6d3c1b232d: add %edi,%eax
0x00007f6d3c1b232f: nop
Loop:
0x00007f6d3c1b2330: vpandd 0x10(%rdx),%zmm0,%zmm1
0x00007f6d3c1b233a: movslq %edi,%r11
0x00007f6d3c1b233d: vmovdqu32 0x10(%rsi,%r11,4),%zmm2
0x00007f6d3c1b2348: vpermd %zmm2,%zmm1,%zmm1
0x00007f6d3c1b234e: neg %r11
0x00007f6d3c1b2351: vmovdqu32 %zmm1,-0x30(%rcx,%r11,4)
0x00007f6d3c1b235c: add $0x10,%edi
0x00007f6d3c1b235f: cmp %eax,%edi
0x00007f6d3c1b2361: jl 0x00007f6d3c1b2330
Specifically: we have this in the loop since then:
vpandd 0x10(%rdx),%zmm0,%zmm1
I also attached an image "C2_graph.png" that shows the C2 graph: it shows 2 LoadVector, and AndV a VectorRearrange and a StoreVector in the loop for JDK26. Before JDK25-ea+2, we would have had one less LoadVector and no AndV in the loop.
C2 does not let the LoadVector for the shuffle vector float out of the loop, because it is on the same int[] slice as the vector load/store from the arrays we are reversing. C2 can at that point not prove that the arrays do not alias.
------------------------------------------------------
I then did some digging into what changes went into jdk-25-ea+2, and
Another note: we should make sure we have better regression tests for these cases. But this is tricky, since the simple IR node counting does not work here. We'd need some way to tell if nodes are in the loop or not (e.g. 1 LoadVector and 0 AndV in loop).
---------------------------------------------------
Note: I only saw a 10% regression with -XX:LoopMaxUnroll=0. I think with sufficient unrolling the cost of the additional instruction is somehow hidden. Still, we should fix this, it is suboptimal to have extra instructions in the loop, and could show on other benchmarks down the line.
- relates to
-
JDK-8373026 C2 SuperWord and Vector API: vector algorithms test and benchmark
-
- Resolved
-