-
Type:
Enhancement
-
Resolution: Unresolved
-
Priority:
 P4
P4
-
Affects Version/s: 27
-
Component/s: hotspot
The current live range splitting algorithm (PhaseChaitin::Split) walks the blocks of the compiled program in reverse postorder only once, and makes decisions greedily. Therefore, when the IR contains loops, the algorithm can take suboptimal decisions at control-flow merges where all predecessors are not yet visited. Specifically, there are two issues that we have seen so far:
1. We may make the wrong UP/DOWN decision, leading to costly spills and register reloads, in the worst case within frequently executed loops (see JDK-8341697).
2. We may start unnecessarily reloading and spilling rematerializable values at control-flow merges for live ranges that have multiple definitions, even when it is possible to prove that only a single rematerializable definition of the value reaches every input to that specific merge.
It is possible to compute the information required to make better decisions (complete reaching definitions and UP/DOWN information), and we should arguably do so. The advantage is that we can get much better compiled code in certain cases. For example, fixing issue 1 above, we have evidence of a 40% execution time improvement for SPECjvm 2008 scimark.sparse.small for aarch64. The disadvantage is that we increase compilation time, but likely marginally.
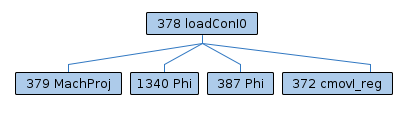
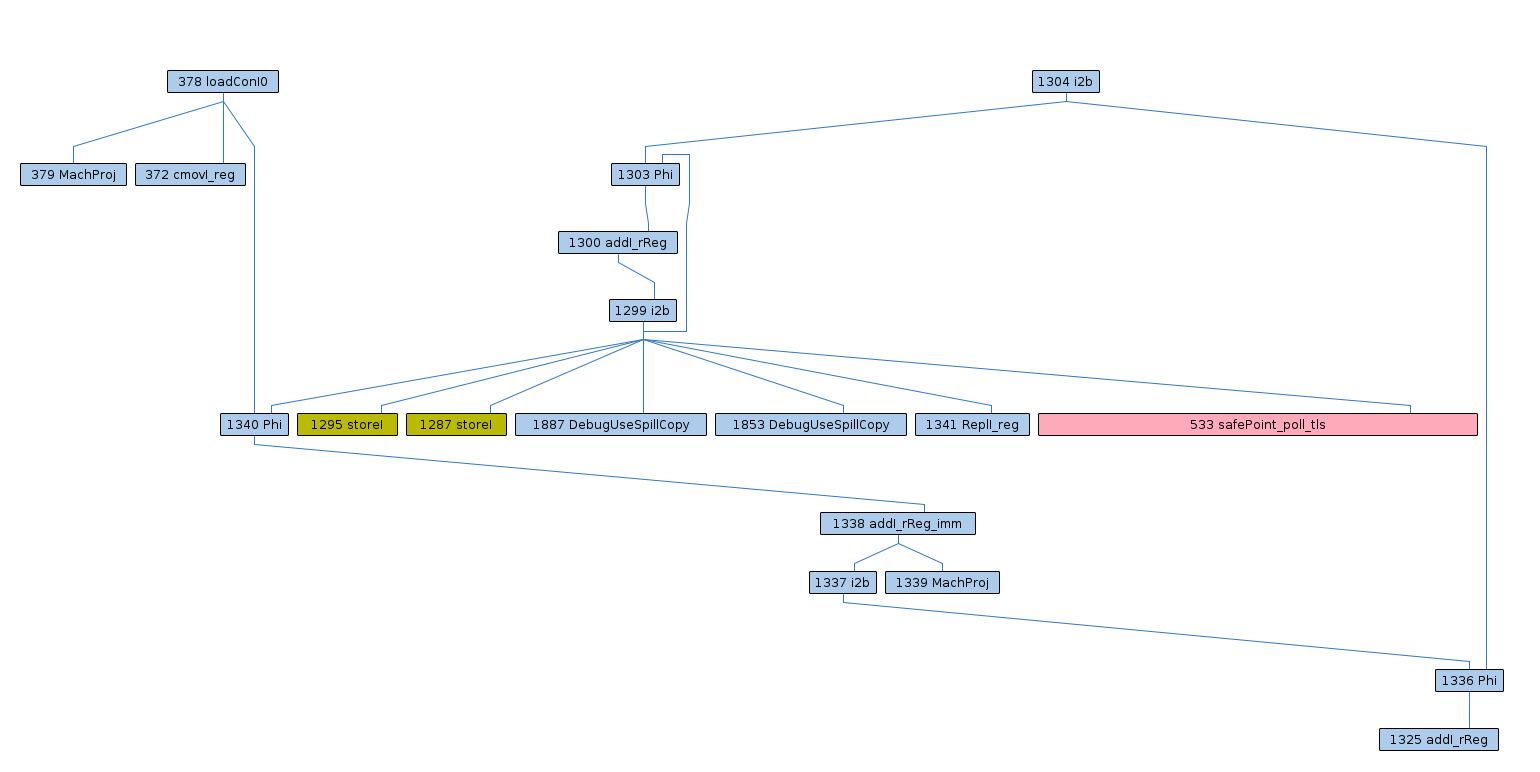
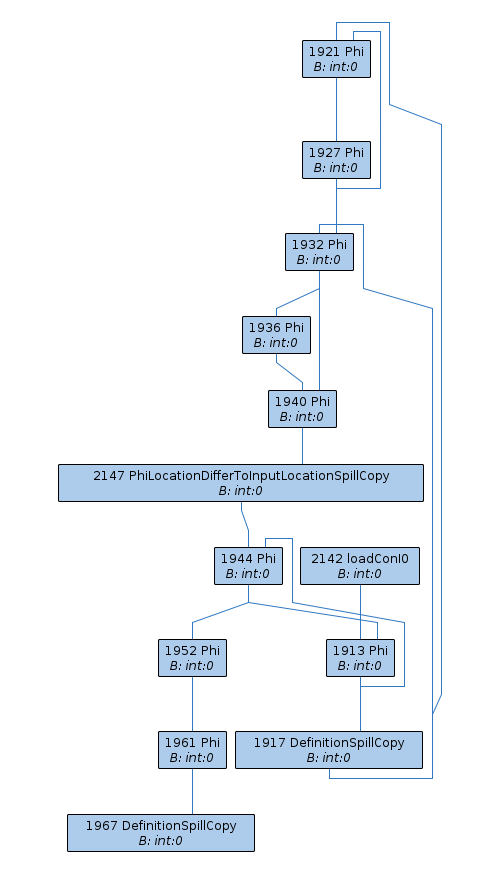
To illustrate issue 2, consider the example compilation (1-initial-liveness.png, 2-aggressive-coalescing.png, 3-initial-spilling.png), found by [~bmaillard]. At 1-initial-liveness, we have a single-definition rematerializable live range, and all is fine. Live range splitting can handle this special case. At 2-aggressive-coalescing, the live range is coalesced with other live ranges, and is no longer single-definition. Therefore, properly rematerializing the part of the live range that is rematerializable is not straightforward, and live range splitting results in 3-initial-spilling, where we rematerialize much too early and subsequently create a number of unnecessary Phis, spills, and reloads.
An alternative solution for issue 2 that we could investigate is to never coalesce single-definition rematerializable live ranges. However, such a solution likely have other detrimental effects.
An overall solution to this issue likely subsumes JDK-8341697, and we could in that case close it as a duplicate issue.
Here is an experimental changeset (inspired by [~qamai]'s proposed changeset for JDK-8341697) that changes PhaseChaitin::Split to run to fixpoint, solving issue 1: https://github.com/openjdk/jdk/compare/master...dlunde:jdk:loop-spilling-8341697+alternative. It is also possible to modify the changeset to also solve issue 2.
1. We may make the wrong UP/DOWN decision, leading to costly spills and register reloads, in the worst case within frequently executed loops (see JDK-8341697).
2. We may start unnecessarily reloading and spilling rematerializable values at control-flow merges for live ranges that have multiple definitions, even when it is possible to prove that only a single rematerializable definition of the value reaches every input to that specific merge.
It is possible to compute the information required to make better decisions (complete reaching definitions and UP/DOWN information), and we should arguably do so. The advantage is that we can get much better compiled code in certain cases. For example, fixing issue 1 above, we have evidence of a 40% execution time improvement for SPECjvm 2008 scimark.sparse.small for aarch64. The disadvantage is that we increase compilation time, but likely marginally.
To illustrate issue 2, consider the example compilation (1-initial-liveness.png, 2-aggressive-coalescing.png, 3-initial-spilling.png), found by [~bmaillard]. At 1-initial-liveness, we have a single-definition rematerializable live range, and all is fine. Live range splitting can handle this special case. At 2-aggressive-coalescing, the live range is coalesced with other live ranges, and is no longer single-definition. Therefore, properly rematerializing the part of the live range that is rematerializable is not straightforward, and live range splitting results in 3-initial-spilling, where we rematerialize much too early and subsequently create a number of unnecessary Phis, spills, and reloads.
An alternative solution for issue 2 that we could investigate is to never coalesce single-definition rematerializable live ranges. However, such a solution likely have other detrimental effects.
An overall solution to this issue likely subsumes JDK-8341697, and we could in that case close it as a duplicate issue.
Here is an experimental changeset (inspired by [~qamai]'s proposed changeset for JDK-8341697) that changes PhaseChaitin::Split to run to fixpoint, solving issue 1: https://github.com/openjdk/jdk/compare/master...dlunde:jdk:loop-spilling-8341697+alternative. It is also possible to modify the changeset to also solve issue 2.
- relates to
-
-
- Open
-